
Semantic and Sequence
미 버클리 대학생 리암 포어(Liam Porr)가 인공지능을 사용해 작성한 블로그 게시물이 IT뉴스 큐레이팅 플랫폼인, 해커뉴스(Hacker News)에서 1위를 차지했다.
© AI TIMES
자연어 처리(National Language Processing, NLP) 분야는 최근 눈부신 속도로 발전하고 있습니다. 그 중심에는 BERT나 ELECTRA와 같은 트랜스포머(transformer) 기반의 언어 모델이 있지만, 트랜스포머 이전에도 Word2Vec과 RNN 등을 활용하여 이미 가파른 성장세를 보이고 있었습니다.
Word2Vec
기존 규칙 기반 모델은 미리 정의된 사전에 의존하거나 통계적 패턴을 활용하여 문제를 해결했습니다. 이러한 방식은 높은 정확도(accuracy)에 비해 낮은 재현율(recall)을 보였고, 같은 모델을 다른 도메인에 적용하면 결과가 좋지 못했습니다. 이러한 규칙 기반 모델은 장점이 명확했지만 확장성이 떨어졌고, 사람들이 실제로 사용하는 언어는 지속적으로 변화했기 때문에 실생활에 적용하기 쉽지 않았습니다. 그로 인해 규칙 기반 모델은 주로 특정 도메인 작업(domain-specific task) 위주로 발전할 수밖에 없었습니다. Word2Vec의 등장은 이러한 문제들을 해결할 돌파구의 시발점이 되었습니다.
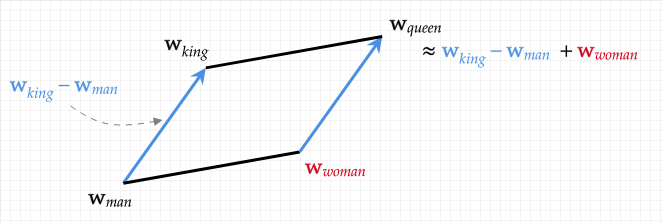
그림 1. Semantic (Word2Vec)
© The University of Edinburgh
Word2Vec 모델이 하는 일은 단순합니다. 단어를 다차원 벡터로 변환시켜주는 임베딩(Embedding) 작업입니다. 여기서 가장 중요한 점은, 변환된 벡터가 단어의 의미적(semantic) 정보를 포함하고 있다는 것입니다.
$$\tag{1} \mathrm{w_\mathcal{king}} - \mathrm{w_\mathcal{man}} + \mathrm{w_\mathcal{woman}} \approx \mathrm{w_\mathcal{queen}}$$
사람에게는 단순해 보이는 수식 1의 넌센스가 Word2Vec 이전의 모델들은 ‘이해(표현)’하지 못했습니다. 하지만 Word2Vec은 신경망(Neural Network) 모델과 CBOW, Skip-gram과 같은 학습 방법론을 통해 벡터에 의미 정보를 담는데 성공해냅니다.
이러한 의미 정보가 중요한 이유에 대해 예시를 통해 설명해 보겠습니다. 예를 들어, ‘강아지’를 자주 검색하는 사람에게 ‘개 사료’를 추천해주고 싶다고 가정해 봅시다. 규칙 기반 모델은 유사한 상품 하나하나를 직접 연결해 주어야 합니다. 하지만 Word2Vec은 학습을 통해 비슷한 의미를 가진 단어들이 유사한 벡터를 갖게 되므로, 알고리즘을 통해 유사 상품들을 쉽게 검색할 수 있습니다.
Sequence
Word2Vec의 등장으로 NLP 분야는 한 걸음 더 나아갔지만, Word2Vec에는 치명적인 한계가 잇었습니다. 자연어 처리에서는 의미(semantic)만큼 문맥(sequence) 또한 중요한데, Word2Vec은 단어에 이러한 문맥을 담아내지 못했습니다.
은결이는 배를 타고 강을 건넜다.
종길이는 과수원에서 배를 땄다.
창석이는 밥을 많이 먹어서 배가 부르다.
우리는 세 문장에서 ‘배’가 가진 의미가 모두 다르다는 것을 알 수 있습니다. 이는 앞뒤 문맥을 통해 의미를 유추할 수 있기 때문입니다. 즉, 같은 단어라도 어떤 문맥에 오는지에 따라 의미가 달라지며, 이를 자연어 처리에서는 단어의 의미가 문맥(sequence)에 의해 결정된다고 표현합니다.
하지만 Word2Vec은 이러한 문맥 정보까지는 표현하지 못하는 한계가 있습니다. 위의 세 문장에서 ‘배’라는 단어를 Word2Vec의 입력으로 넣으면 모두 똑같은 벡터로 변환됩니다. 이 벡터는 ‘타는 배’, ‘먹는 배’, ‘신체의 일부분인 배’의 의미를 모두 포함하고 있지만, 이는 결국 모델 성능의 한계로 이어집니다.
Language Model
앞서 Word2Vec 모델이 하는 역할을 임베딩이라고 설명했습니다. 임베딩 모델과 언어 모델은 모두 입력 텍스트를 벡터로 변환하는 역할을 합니다. 하지만 두 모델 사이에는 큰 차이점이 있습니다. 임베딩 모델은 어떤 문장이 들어오든 같은 단어는 항상 같은 벡터로 변환하지만, 언어 모델은 동일한 문장이 아니라면 같은 단어라도 다른 벡터로 변환합니다.
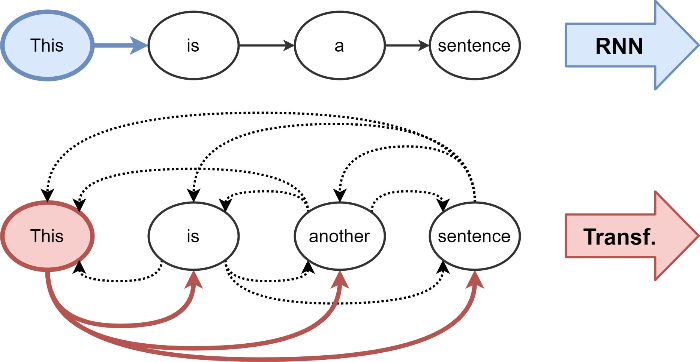
그림 2. Attention mechanism
Chaitanya K. Joshi (2020)
언어 모델은 그림과 같이 해당 단어의 벡터를 계산하기 위해 주변 단어의 정보를 포함합니다. 예를 들어, RNN에서 ‘a’라는 단어의 벡터를 결정할 때는 이전 단어인 [‘This’, ‘is’]의 특징(feature)을 함께 사용하여 최종 벡터를 결정합니다. 트랜스포머의 경우는 양방향(Bi-direction) 인코딩을 사용하는데, 이는 'a'의 벡터를 정할 때 ['This', 'is', 'sentence']와 같이 문장 내 모든 단어의 특징을 포함하여 벡터를 결정한다는 의미입니다.
이처럼 언어 모델은 문맥 정보까지 벡터에 담아낼 수 있게 되었고, 덕분에 자연어 처리 분야는 바야흐로 전성기를 맞이하고 있습니다.
결론
딥러닝 모델을 연구/개발할 때, 다루는 데이터의 특성을 잘 파악하는 것이 가장 중요하다고 생각합니다. 언어라는 데이터의 특성에 대해 알아야 할 개념이 많지만, 그중에서도 의미(Semantic)와 문맥(Sequence)이 가장 핵심이 되는 개념이라고 생각합니다.
Reference
[1] Devlin, Jacob (2019) | BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
[2] K Joshi, Chaianya (2020) | Transformers are Graph Neural Networks
[3] Mikolov, Tomas (2013) | Efficient Estimation of Word Representations in Vector Space
[4] Liu, Yang (2016) | Learning Natural Language Inference using Bidirectional LSTM model and Inner-Attention