
Embedding
임베딩이란 복잡한 고차원 데이터를 연속적인(continuous) 저차원의 벡터 공간으로 변환하는 것
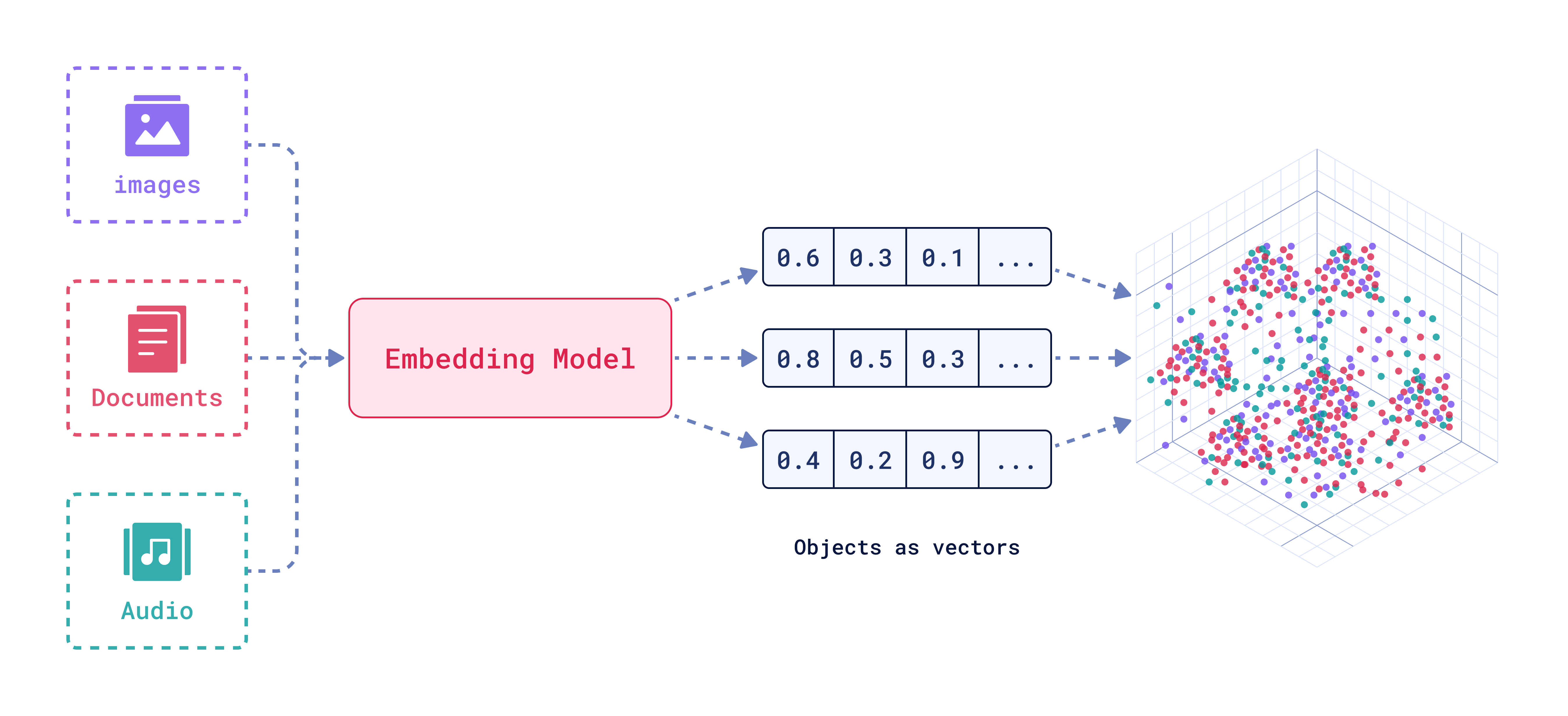
그림 1. Embedding Model Visualization
© Qdrant
100 x 100 크기의 컬러 이미지를 디지털 데이터로 표현하기 위해서는 가로 픽셀 수 100, 세로 픽셀 수 100, 그리고 컬러 채널(일반적으로 RGB)이 3개이므로 100 x 100 × 3 = 30,000 차원이 필요합니다. 그리고 이 데이터의 각 차원은 0에서 255 사이의 정수 값을 가지기 때문에, 소수점 공간에는 데이터가 존재하지 않고 비어있게 됩니다. 임베딩(embedding)의 등장 배경이 바로 여기에 있습니다.
임베딩 모델은 30,000 차원의 이산적인(discrete) 데이터를 512 차원의 연속적인 [-1, 1] 사이 값으로 변환해 줍니다. 이러한 가정이 필요한 주된 이유는 다음과 같습니다.
임베딩의 목적
데이터의 차원 축소 (Dimensionality Reduction)
고차원 데이터는 계산 비용이 높고 저장 공간을 많이 차지하며, 머신러닝 모델의 성능을 저하시킬 수 있습니다. 임베딩은 고차원 데이터를 저차원으로 압축하여 복잡한 데이터를 처리할 때 계산 복잡성을 줄이고 효율성을 높입니다.
데이터의 의미적 표현(Semantic Representation)
임베딩은 데이터의 내재된 구조와 의미를 보존하면서 저차원 공간으로 변환합니다. 의미적으로 가까운 데이터는 벡터 공간에서 가까운 위치에, 의미적으로 먼 데이터는 먼 위치에 배치됩니다. 예를 들어, “개"와 “고양이"는 의미적으로 가깝기 때문에 벡터 공간에서 가까운 위치에 표현되고, “개"와 “자동차"는 의미적으로 멀기 때문에 먼 위치에 표현됩니다.
노이즈 제거 및 일반화(Noise Reduction and Generalization)
고차원 데이터에는 불필요한 정보나 노이즈가 포함될 가능성이 높습니다. 임베딩은 중요한 특징만 추출하여 노이즈를 줄이고, 모델의 일반화 성능을 향상시킵니다. 예를 들어, 이미지 데이터에서 배경 노이즈를 줄이고 주요 객체의 특징만 강조할 수 있습니다.
임베딩은 AI 모델이 실제 데이터를 효과적으로 이해하고 처리할 수 있도록 데이터를 적절한 형태로 변환하는 필수적인 과정입니다. 데이터의 차원 축소, 데이터 간의 관계 표현, 다양한 AI 작업 지원 등 여러 가지 이점을 제공하며, 현대 AI 기술에서 중요한 역할을 담당하고 있습니다.
임베딩의 역사
임베딩의 정확한 기원을 특정하기는 어려운데, 이는 다양한 분야에서 비슷한 아이디어들이 독립적으로 발전했기 때문입니다. 그러나 자연어 처리 분야에서 주로 언급되는 ‘단어 임베딩(word embedding)’을 중심으로 그 발전 과정을 정리해 보면 다음과 같습니다.
분포 가설 (1950년대)
단어의 의미는 해당 단어가 사용되는 맥락에 따라 결정된다는 분포 가설은 임베딩의 이론적 기반이 되었습니다. Zellig Harris를 비롯한 연구자들이 이 개념을 발전시켰습니다.
잠재 의미 분석(LSA, 1980년대 후반)
대규모 텍스트 데이터에서 단어와 문서 간의 관계를 분석해 저차원 벡터 공간으로 표현하는 기법인 LSA(Latent Semantic Analysis)가 등장했습니다.
LSA는 주성분 분석(PCA, Principal Component Analysis) 및 특이값 분해(SVD, Singular Value Decomposition)와 같은 기법을 활용하여 단어-문서 행렬의 차원을 축소하고, 단어 간의 의미적 유사성을 파악합니다. 이는 단어 임베딩의 초기 형태로 간주됩니다. (참고)
Word2Vec (2013)
2003년 Bengio et al.의 Neural Probabilistic Language Model은 신경망을 사용하여 단어 표현을 학습하는 방법을 제안하며, 신경망을 이용한 임베딩 연구의 중요한 기반을 마련했습니다.
이 후, Mikolov et al.이 개발한 Word2Vec은 CBOW와 Skip-gram이라는 효율적인 학습 알고리즘을 통해 고품질의 단어 임베딩을 생성하는 방법을 제시했습니다. 이는 임베딩 기술이 본격적으로 확산되는 중요한 전환점이 되었습니다.
BERT (2018)
Google에서 개발한 BERT(Bidirectional Encoder Representations from Transformers)는 Transformer라는 획기적인 신경망 구조를 기반으로, 양방향 문맥 정보를 모두 활용하여 단어 및 문장 임베딩을 생성합니다.
BERT는 문맥을 고려한 임베딩(contextualized embedding)을 생성하여 다양한 자연어 처리 태스크에서 획기적인 성능 향상을 보여주었습니다.
딥러닝 기반 임베딩
현재 활용되는 임베딩은 대부분 딥러닝 기반입니다. 딥러닝 기반 임베딩은 기존 방식과 달리 특징(feature)을 자동으로 추출합니다. 이전에는 사람이 일일이 특징을 설계해야 했지만, 딥러닝 기반 임베딩은 모델이 데이터 패턴을 분석해 스스로 특징을 학습합니다.
이러한 딥러닝 기반 임베딩 모델로는 Word2Vec, GloVe, FastText 등이 있었지만, 현재는 Transformer 인코더 기반의 BERT 모델이 주로 활용됩니다.
BERT가 기존 모델과 가장 큰 차이점은 동음이의어를 구분한다는 것입니다. Word2Vec 등은 ‘옳다(right)‘와 ‘오른쪽(right)‘을 구별하지 못해, 모든 ‘right’를 동일한 벡터로 표현했습니다. 그러나 BERT는 문맥에 따라 단어에 다른 임베딩 값을 부여합니다.
더 나아가, BERT는 같은 ‘오른쪽(right)‘이라도 문맥에 따라 매번 다른 임베딩 값을 출력합니다. 이는 BERT가 “오른쪽(right)“이라는 단어의 문맥상 의미를 정확히 포착하고 있음을 보여줍니다. 이러한 BERT의 특징 덕분에, 딥러닝 기반 임베딩은 현재 다양한 분야에서 널리 사용되고 있습니다.
딥러닝 기반 임베딩의 한계
현재 임베딩은 딥러닝 모델을 활용하여 데이터를 벡터로 표현하는 기술입니다. 이 과정에서 모델은 데이터 간의 통계적 관계를 알아서 학습하고 이를 벡터 공간에 반영합니다. 이러한 자동화는 매우 유용하지만, 사용자가 특정 의도를 가지고 임베딩을 제어하기 어렵게 만드는 측면도 있습니다.
예를들어 사용자가 “왕"과 “거지"라는 특정 단어를 원하는 거리 또는 방향으로 배치하기 위해 의도적으로 개입하는 것은 불가능합니다. 임베딩 벡터는 모델이 데이터로부터 추출한 통계적 의미에 따라 자동으로 결정되기 때문입니다.
딥러닝 모델은 내부 작동 방식을 해석하기 어려운 “블랙박스"로 여겨지곤 합니다. 임베딩 역시 딥러닝 모델을 통해 생성되므로, 특정 단어나 데이터가 왜 그리고 어떻게 특정 위치에 배치되었는지 정확히 파악하기 어렵습니다. 이는 임베딩 결과를 완벽하게 이해하고 제어하는 것을 어렵게 만듭니다.
Reference
[1] Aquino, Sabrina (2024) | What are Vector Embeddings? - Revolutionize Your Search Experience
[2] Lee, Gichang (2017) | SVD와 PCA, 그리고 잠재의미분석(LSA)