
Scaling Laws
2025년 7월 11일, 중국의 Moonshot AI에서 1 Trillion(1조)의 모델 크기를 가지는 Kimi K2를 공개했습니다. MoE(Mix-of-Experts) 구조를 적용해 실제 활성 파라미터(Activated Parameters)는 32B에 불과하지만, 높은 벤치마크(Benchmark) 성능을 기록하며 대형 언어 모델(Large Language Model, LLM) 크기 논란에 다시 불을 지폈습니다.
| Model | Model Size | Training Tokens |
|---|---|---|
| Gemma 3 | 27B | 14T |
| Qwen3 | 32B | 36T |
| PANGU-Σ | 1T | 329B |
| Kimi K2 | 1T | 15.5T |
| Llama 4 Behemoth | 2T | 30T |
표 1. 대형 언어 모델별 모델의 크기와 사전 학습에 사용된 데이터의 양
최근 공개된 Gemma 3나 Qwen3와 같은 오픈 소스 파운데이션 모델들은 최신 GPT나 Gemini만큼의 성능은 아니지만, 충분히 준수한 출력을 생성합니다. 체감상으로 과거 GPT-3.5나 Gemini 1.5와 비슷하거나 그 이상이라고 느껴질 정도입니다. 게다가 Kimi K2는 벤치마크에서 최신 GPT와 Gemini를 능가할 만큼 높은 성능을 보여줍니다. 이 놀라운 성능의 배경에는 1T 파라미터라는 어마어마한 모델 크기가 있습니다.
그런데 흥미로운 점은, Kimi K2가 공개되기 2년 전에 화웨이가 이미 PANGU-Σ (Xiaozhe Ren, et al. 2023)라는 1T 모델을 발표했다는 것입니다. 이때 PANGU-Σ가 주목받지 못한 이유는 공개 당시 자신보다 약 80배 작은 GPT-3 13B 모델과 비슷한 벤치마크 성능을 보였기 때문입니다. Kimi K2와 PANGU-Σ가 같은 크기의 모델임에도 불구하고 거의 2세대 가까운 성능의 차이가 발생한 이유는 크게 두 가지를 꼽을 수 있습니다. 첫 번째로는 RLHF(Reinforcemenet Learning from Human Feedback)와 같은 강화학습이 시행되지 않았다는 점, 그리고 두 번째로 사전 학습에 사용된 데이터의 양이 너무 적었다는 점입니다.
이번 글에서는 이 ‘데이터의 양’에 대해 집중적으로 살펴보겠습니다.
Underfitting
초기 Transformer 인코더 기반의 언어 모델인 BERT (Jacob Devlin, et al. 2018)가 공개되었을 때만 해도 언어 모델의 크기는 110M(BERT-base)에 불과했습니다. 그리고 BERT 학습에 사용된 사전 학습 데이터의 용량은 13GB 였으며, 이는 대략 2B+ tokens로 추정됩니다.
| Model | Model Size | Training data size | Training tokens (approximate) |
|---|---|---|---|
| BERT-base | 110M | 13GB | 2B+ |
| BERT-large | 335M | 13GB | 2B+ |
| RoBERTa-base | 125M | 160GB | 20B+ |
| RoBERTa-large | 355M | 160GB | 20B+ |
표 2. 과거 언어 모델별 모델의 크기와 사전 학습에 사용된 데이터의 양
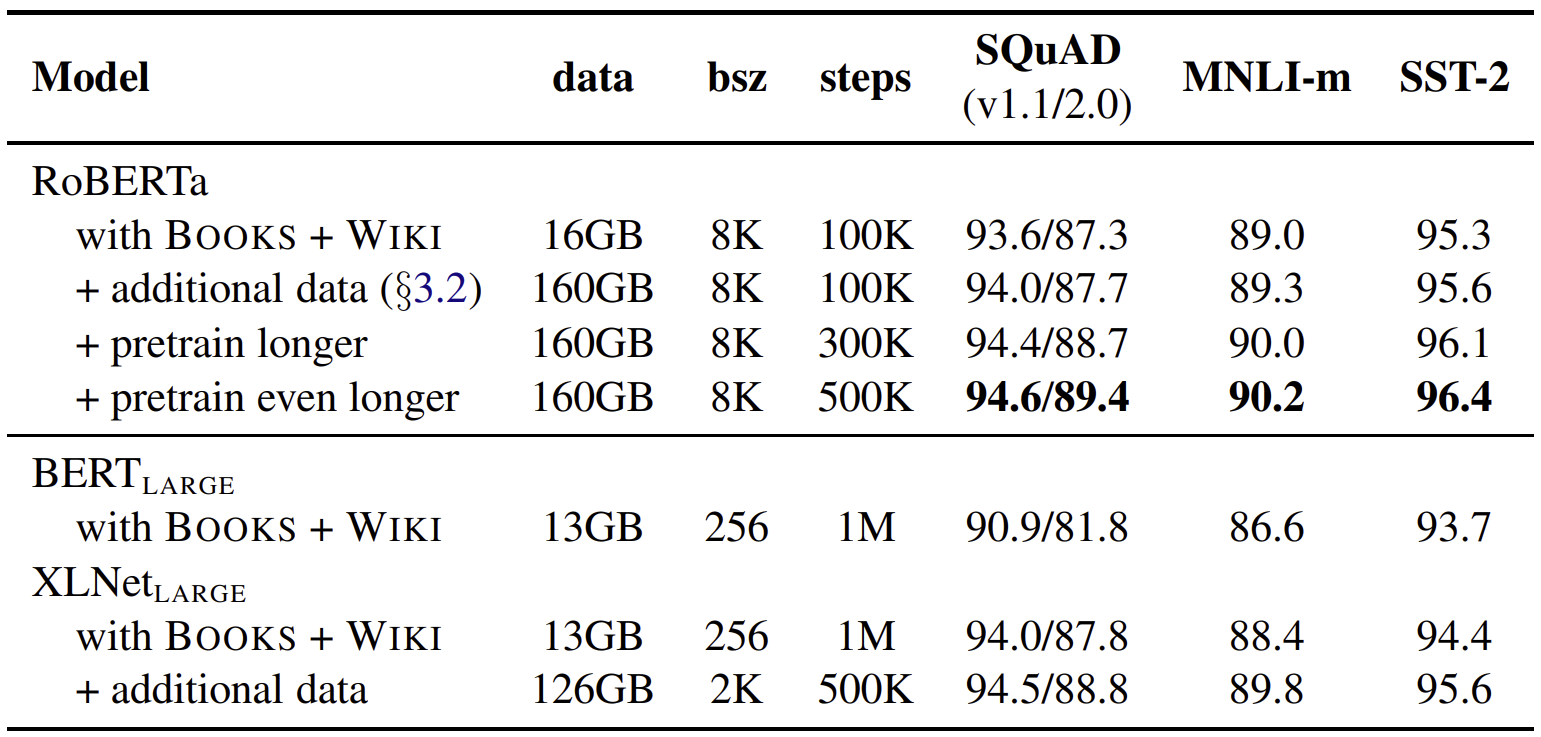
그림 1. Compare with BERT and RoBERTa
Yinhan Liu, et al. (2019)
표 2를 보면 과거의 언어 모델의 크기는 최근의 대형 언어 모델들의 크기에 비하면 상당히 작다는 것을 확인할 수 있습니다. 그렇다면 왜 과거에는 모델의 크기를 늘리지 않았던 걸까요? 그 이유는 그림 1에서 확인할 수 있습니다.
그림 1의 핵심은 BERT가 학습 부족(undertrained) 상태라는 점입니다. 딥러닝 모델은 학습 데이터를 활용해 모델의 가중치를 최적화합니다. 당연하게도 이때 충분한 학습 데이터를 확보해야 모델을 제대로 학습시킬 수 있습니다. 만약 모델을 최적화할 만큼 충분한 데이터셋을 확보하지 못했다면, 두 종류의 문제점이 발생할 수 있습니다.
첫 번째는 데이터셋의 양이 적을 때 모델을 무리하게 학습시킬 경우 과적합(Overfitting)이 발생할 수 있습니다. 이는 학습 데이터에는 제대로 반응하지만, 학습 과정에서 보지 못한 새로운 데이터가 들어왔을 때는 제대로 동작하지 않는 현상 입니다.
최근 LLM에서 발생하는 환각(Hallucination)이 과적합 문제의 한 예시라고 볼 수 있습니다. 결국 과적합은 일반화 능력이 부족하기에 발생하는 현상이며, 이는 모르는 걸 모른다고 말하게 만드는 학습 데이터가 부족했기 때문에 발생하는 문제입니다.
두 번째는 모델 크기에 비해 데이터셋의 크기가 작으면 학습 부족이 발생하는 문제입니다. BERT를 학습시켰던 13GB의 데이터셋으로 BERT의 10배, 100배 더 큰 모델을 학습시키려고 하면, 오히려 오차율(Error rate)이 더 높아지게 됩니다.
Scaling Laws
2020년 1월 OpenAI에서 Sacling Laws for Neural Language Models(Jared Kaplan, et al.)을 발표합니다. 해당 논문의 연구 주제는 모델 크기와 데이터셋 크기의 상관관계를 분석하고 모델 크기에 따른 최적의 데이터셋 크기를 찾는 것입니다.
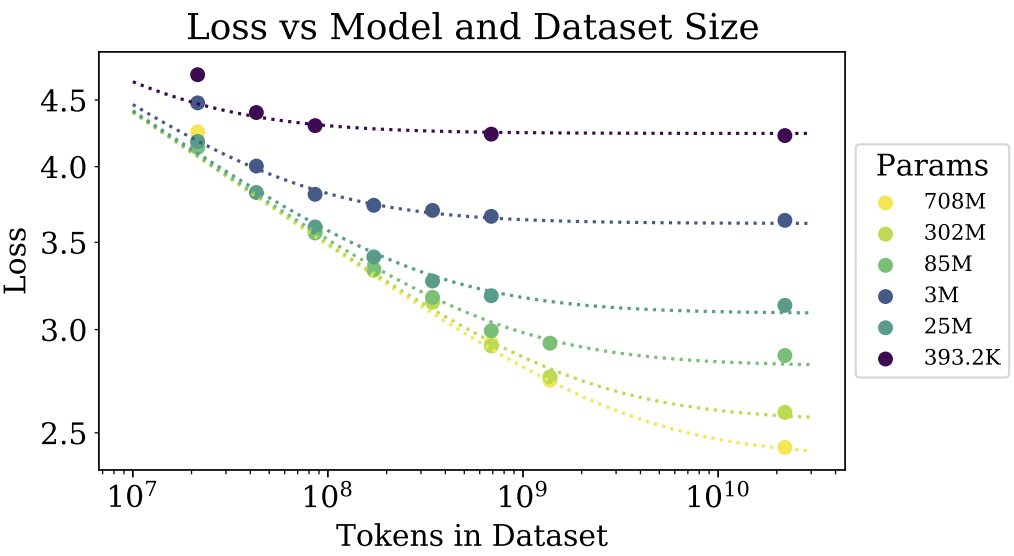
그림 2. 모델 크기와 데이터셋 크기에 따른 test loss
Yinhan Liu, et al. (2019)
Scaling Laws 논문에는 다양한 분석 지표들이 존재하지만, 가장 핵심은 그림 2의 모델 크기와 데이터셋 크기에 따른 Test Loss 값입니다. 그림 2를 보면 $10^8$ Tokens(X-축) 이하의 데이터에서 708M Params 모델이 302M Params 모델과 같거나 더 낮은 성능을 보이고 있습니다. 이는 데이터의 양이 작다면 모델의 크기를 키우더라도 성능이 오르지 않거나 오히려 하락할 수 있다는 것을 보여줍니다.
$$ \begin{cases} -4x + 3y = -8\\\ 7x - 4y = 14 \end{cases} $$
딥러닝은 기본적으로 데이터를 활용해 모델이라는 연립 방정식의 해를 찾는 작업입니다. 예를 들어, 2차 연립 방정식은 2개 이상의 정답셋이 필요하고, 3차 연립 방정식은 3개 이상이 필요합니다. 모델의 크기를 늘리는 것은 연립 방정식의 차원을 늘리는 행위이며 이는 곧, 차원이 늘어난 만큼의 데이터가 더 필요하다는 얘기입니다.
즉, 모델의 크기에 비해 데이터가 적다면 모델은 최적해에 결코 도달할 수 없습니다. 오히려 불확실성이 높아져서 성능이 저하될 뿐입니다.
결론
BERT와 RoBERTa 그리고 ALBERT(Zhenzhong Lan, et al. 2019)가 공개되면서 연구자들은 ‘데이터의 양에 비해 모델의 파라미터 수가 너무 많다.’ 라는 사실을 깨닫게됩니다. 파라미터 수가 더 적은 ALBERT의 성능이 BERT 보다 더 뛰어났기 때문입니다.
이러한 연구 결과를 바탕으로 최근에는 학습 데이터의 양이 기하급수적으로 늘어나서, 대부분의 파운데이션 모델이 사전 학습에 10T 토큰 이상을 사용하고 있습니다. 그리고 데이터 양이 증가함에 따라 모델의 크기 또한 상응할 만큼 커졌습니다. 초기 BERT에 비하면 데이터는 5,000배 이상 그리고 모델 크기는 300배 이상 커진 것 입니다.
Kimi-K2는 1T 모델이지만, 실제 Active Parameter는 32B에 불과합니다. Expert의 수를 늘려서 1T 모델을 학습했으나, 32B 라는 Active Parameter 그리고 384라는 Expert의 수가 최적화된 수치라고 보기는 어렵습니다. 현재 27B 모델에 14T 토큰을 1회 학습하는 데 한화로 약 13억 원이 필요합니다. 단순히 비용만 해결된다고 되는 것도 아닙니다. 학습에는 최소 H100 GPU 1,000장 많게는 수만 장이 필요합니다. 게다가 GPU 1,000장 기준으로 1회 학습하는 데만 26일이 소요됩니다.
이러한 점들을 고려할 때, 수천억 원과 수개월을 들여 데이터 크기와 모델 크기의 상관관계를 연구하기보다는 다른 측면에 집중하는 편이 더 효율적이라고 생각합니다. 그럼에도 불구하고 알아야 할 중요한 사실은 단순히 모델의 크기를 키우는 것이 성능 향상으로 직결되지 않는다는 것입니다.
Reference
Devlin, Jacob (2018) | BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Lan, Zhenzhong (2019) | ALBERT: A Lite BERT for Self-supervised Learning of Language Representations
Liu, Yinhan (2019) | RoBERTa: A Robustly Optimized BERT Pretraining Approach
Ren, Xiaozhe (2023) | PanGu-Σ: Towards Trillion Parameter Language Model with Sparse Heterogeneous Computing