
Synthetic Text Image (1/3)
합성 데이터(synthetic text image)는 OCR 학습을 위해 데이터를 기계적인 방법으로 증강(data augmentation)하는 것을 의미합니다. 이전 글에서 설명했듯이, OCR 데이터는 수집 및 가공에 많은 어려움이 따릅니다. 현실에서 다양한 형태의 OCR 데이터를 충분히 수집할 수 있다면 가장 이상적이겠지만, 이는 현실적으로 어렵습니다. 따라서 합성 데이터는 모델 학습을 위한 훌륭한 차선책이 될 수 있습니다.
이번 글에서는 합성 데이터 중에서도 MjSynth와 SynthText에 대해 자세히 설명하고자 합니다. 이 두 데이터셋은 Scene Text OCR 분야에서 대규모 고품질 학습 데이터의 선구적인 역할을 수행했습니다.
MjSynth
MJSynth (MJ)는 장면 텍스트 인식(Scene Text Recognition, STR)에 특화된 데이터셋입니다. 즉, 이미지 내의 텍스트를 정확하게 판독하는 모델을 훈련하는데 사용됩니다. 이 데이터셋은 약 890만 개의 단어 이미지(word box images)를 포함하며, 약 90,000개의 영어 단어와 1,400개 이상의 다양한 폰트를 활용하여 생성되었습니다. 아쉽게도 MJ는 합성 데이터 생성 코드를 제공하지 않습니다.

그림 1. Pipeline of MJSynth
Max Jaderberg, et al. (2014)
MJ 데이터는 다음 과정을 거쳐 생성됩니다. 먼저, 방대한 텍스트 사전에서 추출된 단어들을 다양한 폰트로 렌더링합니다.이 후 실제 배경 이미지 위에 렌더링된 단어를 투영하고, 왜곡, 회전, 굽힘과 같은 기하학적 변형을 적용합니다. 마지막으로 색상, 명암, 노이즈, 블러 등의 조명 효과를 추가하여 자연스럽게 블렌딩하는 과정을 거칩니다.
이렇게 생성된 데이터는 텍스트 내용과 위치 정보가 자동으로 생성되므로, 별도의 추가 작업 없이 STR 모델 학습에 즉시 사용 가능합니다. 다만 MJ 데이터셋은 장면 텍스트 감지(Scene Text Detection, STD) 모델 학습에는 사용할 수 없기에, OCR 시스템 구축을 위해서는 별도의 데이터셋 확보가 필요합니다.
SynthText
SynthText (ST)는 STD 모델 훈련을 위해 설계된 데이터셋입니다. 이 데이터셋은 약 80만 개의 실제 배경 이미지 위에 800만 개에 달하는 합성 텍스트 인스턴스를 자연스럽게 오버레이하여 생성되었으며, 이때 텍스트가 배경의 3D 기하학적 구조를 반영하도록 했습니다. 각 텍스트 인스턴스에는 텍스트 문자열뿐만 아니라 단어 및 문자 수준의 바운딩 박스 주석이 함께 제공되어, 텍스트 감지뿐만 아니라 인식 모델 학습에도 유연하게 활용할 수 있습니다.

그림 2. Poisson Image Editing
Patrick Pérez (2003)
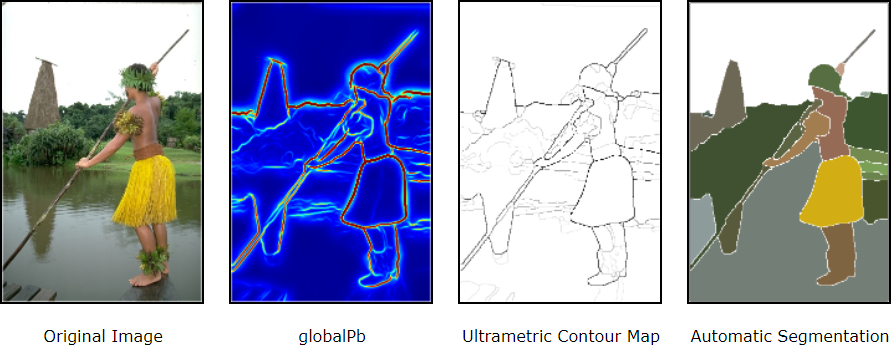
그림 3. Contour Detection and Hierarchical Image Segmentation
Pablo Arbeláez (2010)
ST 데이터셋에서 가장 중요했던 부분은 합성 데이터와 실제 데이터 간의 간극을 줄이는 것이었습니다. 이는 합성 데이터의 주요 단점인 과적합(Overfitting) 문제를 해결하기 위함입니다. 만약 합성 시나리오를 지나치게 제한하면 다양한 데이터를 확보하기 어려워 모델이 실제 텍스트 영역을 인식하지 못하는 과적합이 발생할 수 있습니다. 반대로 시나리오 제한을 해제하여 너무 자유롭게 합성할 경우, 실제 데이터와의 간극이 벌어져 텍스트가 아닌 영역을 텍스트로 오인식하는 과적합이 발생할 수 있습니다.
ST는 이러한 문제점을 해결하기 위해 포아송 객체 편집(Poisson Image Editing)과 gPb-UCM(Global Probability of Boundary - Ultrametric Contour Map) 등의 기법을 활용했습니다. 이 두 기법을 통해 합성 데이터가 실제 배경 이미지에 더욱 자연스럽게 어우러지도록 함으로써 실제 데이터와의 간극을 효과적으로 줄일 수 있었습니다. 그 결과, 기존에는 합성하기 어려웠던 복잡한 시나리오의 데이터도 대규모로 생성할 수 있게 됐습니다.

그림 4. 올바른 합성 이미지 (L) / 잘 못된 합성 이미지 (R)
Ankush Gupta (2016)
그림 4의 왼쪽 이미지는 ST 데이터셋의 샘플이고, 오른쪽 이미지는 필자가 직접 합성한 이미지입니다. 한눈에 봐도 알 수 있듯이, ST 데이터셋의 이미지는 합성 데이터라고 말하지 않으면 모를 정도로 자연스럽습니다. 반면, 오른쪽 필자의 이미지는 합성했다는 티가 분명히 납니다. 이처럼 간단한 예시만으로도 자연스러운 이미지 합성이 얼마나 중요한지 알 수 있습니다.
Reference
[1] Arbeláez, Pablo (2010) | Contour Detection and Hierarchical Image Segmentation
[2] Gupta, Ankush (2016) | Synthetic Data for Text Localisation in Natural Images
[3] Jaderberg, Max (2014) | Synthetic Data and Artificial Neural Networks for Natural Scene Text Recognition
[4] Pérez, Patrick (2003) | Poisson Image Editing