
Synthetic Text Image (2/3)
최근 장면 텍스트 인식(Scene Text Recognition, STR) 분야의 상위 5개 SOTA(State-of-the-Art) 모델들은 벤치마크 학습에 주로 MJSynth(MJ)와 SynthText(ST)를 사용했습니다. 이는 MJ와 ST만으로도 준수한 성능의 모델을 학습할 수 있고, 벤치마크 비교 시 동일한 데이터셋으로 학습된 모델들 간의 비교가 해당 아키텍처의 우수성을 객관적으로 증명하는 데 유용하기 때문입니다.

그림 1. Sample of SynthTiger
Moonbin Yim, et al. (2021)
하지만 MJ와 ST에 견줄 만한 다른 양질의 합성 데이터셋들도 많습니다. 그중에 하나인 SynthTIGER를 이번 글에서 소개하고자 합니다.
SynthTIGER
SynthTIGER는 MJ와 ST를 뛰어넘는 여러 특징을 선보입니다. 특히 노이즈 처리의 정교함, 텍스트 길이와 희귀 문자 분포 정규화, 그리고 모듈화된 생성 파이프라인을 통해 STR 모델 성능 개선에 크게 기여했습니다.
노이즈 처리의 정교함
MJ가 폰트 렌더링, 테두리, 그림자 등 마이크로 레벨의 텍스트 자체에 집중했다면, SynthTIGER는 매크로 레벨 노이즈(예: 텍스트 영역에 다른 단어의 일부가 겹치는 현상)까지 반영하여 실제 데이터의 복잡성을 더욱 정교하게 모방합니다.
텍스트 길이 및 희귀 문자 분포 정규화
MJ는 약 90,000개의 영단어로 사전을 구성했지만, 이로 인해 길거나 짧은 단어의 수가 적고 자주 사용되지 않는 희귀 문자들이 충분히 샘플링되지 못하는 문제가 있었습니다. SynthTIGER는 데이터 정규화를 통해 길이 분포와 문자 분포를 증강하여 데이터가 훨씬 더 고르게 분포되도록 개선했습니다.
모듈화된 유연한 생성 파이프라인
SynthTIGER는 텍스트 형태 선택, 스타일, 변환, 블렌딩, 후처리 등 다섯 가지 핵심 절차로 구성된 모듈화된 파이프라인을 제공합니다. 이는 사용자가 각 단계를 세밀하게 제어하고 다양한 조합으로 특정 시나리오에 맞는 데이터를 유연하게 생성할 수 있게 합니다. 이러한 모듈화 덕분에 MJ나 ST보다 더 다양한 텍스트 효과와 변형(예: 곡선 텍스트, 다양한 원근 변환)을 지원하며 생성되는 데이터의 다양성을 극대화합니다.
Text Rendering Process
SynthTIGER는 실제 텍스트 이미지의 복잡성을 효과적으로 모방하고자 모듈화된 5단계 텍스트 렌더링 파이프라인을 활용합니다. 이 파이프라인은 단순한 텍스트 생성에 그치지 않고, 현실적인 노이즈와 다양한 시각적 변형을 통합하여 STR 모델 학습에 최적화된 데이터를 만들 수 있도록 돕습니다.
SynthTIGER의 5단계 렌더링 파이프라인은 다음과 같이 구성됩니다:
(a) 텍스트 형태 선택 (Text Shape Selection) / (b) 텍스트 스타일 선택 (Text Style Selection) /
(c) 변환 (Transformation) / (d) 블렌딩 (Blending) / (e) 후처리 (Post-processing)

그림 2. Rendering effect visualization of SynthTIGER modules
Moonbin Yim, et al. (2021)
(a), (b), (c) 단계는 기존 MJ와 유사하게 폰트, 색상, 스타일 효과 등을 선택하고 곡선화(curved), 늘이기(stretch), 기울이기(skew), 회전(rotate)과 같은 변환을 적용하여 텍스트를 변형합니다. 이러한 과정은 미시적 수준의 노이즈(마이크로 레벨 노이즈)를 생성하는 데 해당합니다.
그다음 (d) 블렌딩 단계에서는 텍스트와 배경을 자연스럽게 합성하는데, 이때 SynthTIGER는 거시적 수준의 노이즈(매크로 레벨 노이즈, 예: 텍스트 영역에 다른 단어의 일부가 겹치는 현상)를 추가로 반영하여 현실감을 높입니다.
마지막으로 (e) 후처리 단계에서는 추가적인 시각적 효과를 통해 더욱 현실적인 외관을 완성합니다.
이러한 모듈화된 프로세스를 통해 SynthTIGER는 훨씬 더 다양한 텍스트 이미지 데이터를 생성할 수 있습니다. 각 단계는 독립적으로 제어 가능하기 때문에, 사용자는 특정 시나리오에 맞는 데이터를 유연하게 생성할 수 있다는 장점이 있습니다.
Text Selection Strategy
합성 데이터 생성 시에 ‘어떤 텍스트를 이미지에 넣을 것인가’를 결정하는 텍스트 선택 전략은 정말 중요한 단계입니다. 왜 핵심적인지 아래 예시들을 통해 직관적으로 이해할 수 있습니다.

그림 3. Noise가 심한 예제 데이터
위 그림 3처럼 노이즈가 심한 이미지도 우리는 해당 단어가 “컴퓨터"라는 것을 쉽게 예측할 수 있습니다. 마지막 글자만 놓고 보면 “티, 터, 타” 등의 여러 글자가 가능하지만, 단어의 연속적인 흐름 속에서 “컴퓨터"일 확률이 가장 높다고 판단하기 때문입니다.
이처럼 우리가 장면 속 글자를 예측하는 데 단순히 시각 정보뿐만 아니라, 언어라는 특성에 크게 의존한다는 걸 알 수 있습니다. STR 모델 역시 다양한 단어 예제들을 학습하면서 이러한 언어적 ‘경향성’을 배우게 되고, 이는 예측 결과에 지대한 영향을 미칩니다.
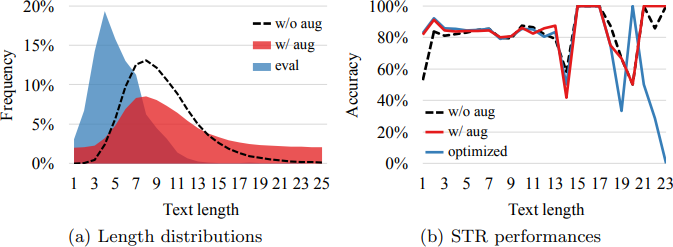
그림 4. Text length distribution of training data
Moonbin Yim, et al. (2021)
그림 4는 텍스트 길이 정규화(Text Length Normalization)의 효과를 보여줍니다. 텍스트 길이를 정규화하지 않은 경우보다 대부분의 구간에서 더 나은 정확도를 보이는 것을 확인할 수 있습니다. 심지어 평가 데이터로 학습된 최적화 모델과 비교했을 때도, 정규화된 데이터를 이용하여 학습한 모델이 평균적으로 더 우수한 성능을 나타내는 것을 확인할 수 있습니다.
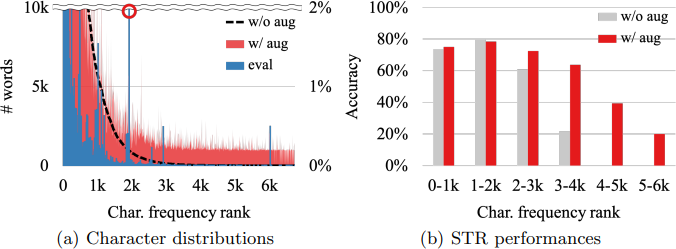 Figure 6. STR accuracy by character distributions
Figure 6. STR accuracy by character distributions
그림 5. Character distribution of training data
Moonbin Yim, et al. (2021)
마지막으로 그림 5는 희귀 문자 정규화의 효과를 보여줍니다. 희귀 문자를 정규화하지 않은 경우보다 정확도가 확연하게 높은 것을 확인할 수 있습니다.
이처럼 STR 모델 학습에서 데이터의 품질을 좌우하는 텍스트 선택 전략의 중요성을 확인할 수 있습니다. 이는 모델이 현실의 복잡하고 다양한 텍스트를 더욱 강건하게(robustly) 인식하도록 돕는 핵심 요소입니다.
Reference
[1] Gupta, Ankush (2016) | Synthetic Data for Text Localisation in Natural Images
[2] Jaderberg, Max (2014) | Synthetic Data and Artificial Neural Networks for Natural Scene Text Recognition
[3] Yim, Moonbin (2021) | SynthTIGER: Synthetic Text Image GEneratoR Towards Better Text Recognition Models