
Synthetic Text Image (3/3)
앞서 MJSynth(MJ), SynthText(ST), 그리고 SynthTIGER 데이터셋에 대해 살펴보았습니다. 해당 데이터셋들은 현실의 실제 배경 사진 위에 가상의 글자를 덧씌워서 생성한 데이터입니다. 이들은 모두 실제 배경 사진에 가상의 글자를 합성하는 방식으로 생성된 데이터입니다. 이 방법은 단순하지만 효과적이고 강력한 방법입니다. 그렇다면 이 방법만으로 충분하다고 볼 수 있을까요. 이번 글에서는 기존 합성 데이터셋과 차별화된 색다른 데이터 생성 방법을 소개해 드리겠습니다.
UnrealText

그림 1. Sample of UnrealText
Shangbang Long, Cong Yao (2020)
UnrealText는 3D 그래픽 엔진(Unreal Engine 4.22)을 활용해 Scene Text Image를 합성하는 방법을 제시했습니다. 그림 1의 예시 이미지를 보면, 3D 오브젝트의 그림자나 장애물을 활용해 실제에 가까운 예제들을 생성하는 것을 확인할 수 있습니다. 이는 ST와 같은 기존 배경 사진 기반 합성 방식으로는 구현하기 어려운 부분입니다.
기존 배경 사진 기반의 합성 방식에서는 광원과 오브젝트 정보를 활용하는 것은 불가능에 가깝습니다. 하지만 UnrealText는 광원, 오브젝트, 텍스처 등을 자유롭게 조작할 수 있으며, 이들이 한데 어우러져 더욱 현실감 있는 합성 데이터를 생성할 수 있다는 장점이 있습니다.
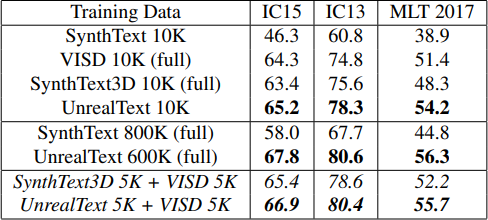
그림 2. Detection results of Mask R-CNN
Shangbang Long, Cong Yao (2020)
특히 주목할 점은 ST와 동일한 양의 학습 데이터로 더 높은 성능의 Scene Text Detection 모델을 생성할 수 있다는 것입니다. 샘플 이미지의 그래픽 에셋 품질이 그리 높지 않았다는 점을 고려하면, 실사에 가까운 고품질의 에셋을 사용할 경우 더 큰 성능 향상이 기대됩니다. 데이터 합성 과정의 다양성 측면에서는 아쉬운 점이 분명 존재하지만, 3D 그래픽 엔진을 활용해 OCR 학습 데이터를 생성하는 아이디어 자체는 주목할 만하다고 판단됩니다.
SRNet
Style Retention Network(SRNet)은 자연 이미지에 있는 텍스트를 딥러닝 모델을 이용하여 수정하는 작업에 대해 다룹니다. 해당 작업의 목표는 원본 이미지의 텍스트 스타일과 배경을 자연스럽게 유지하면서, 시각적으로 구별하기 어려울 정도로 완벽하게 편집된 이미지를 생성하는 것입니다.

그림 3. (L) Original, (R) Replaced
Liang Wu, et al. (2019)
이 방식은 새로운 데이터의 생성보다는 데이터 증강(data augmentation)에 가깝기 때문에, 모델 성능을 획기적으로 높이기는 어렵습니다. 하지만 실제 데이터와 매우 유사하기 때문에, 상대적으로 데이터 양이 부족한 소수(minor) 언어의 데이터를 확보하는 데 유용하게 활용될 수 있습니다.
결론
기존의 MJSynth, SynthText부터 개선된 SynthTIGER, 새로운 패러다임을 제시한 UnrealText와 SRNet까지 다양한 합성 데이터에 대해 알아보았습니다. OCR 모델의 성능은 이미 높은 수준에 도달했지만, 소수 언어의 경우 여전히 데이터 부족 문제가 존재합니다. 한국어 문서 및 장면 인식에서 이러한 합성 데이터를 활용하는 것은 이제 선택이 아닌 필수입니다. 미리 알아두면 분명 도움이 될 것입니다.
Reference
[1] Long Shangbang (2020) | UnrealText: Synthesizing Realistic Scene Text Images from the Unreal World
[2] Wu Liang (2019) | Editing Text in the Wild