
Scene Text Recognition (1/2)
장면 문자 인식(Scene Text Recognition, STR)은 기본적인 이미지 분류(Image classification) 작업과 유사하게 동작합니다. 이미지 분류 모델이 이미지를 입력받아 해당 이미지의 분류 라벨을 출력하는 것처럼, STR 모델은 이미지를 입력받아 이미지 안의 글자 라벨을 출력합니다. 여기서 한 가지 다른 점은 일반적인 이미지 분류 작업의 라벨에는 ‘시퀀스(sequence)’ 정보가 없다는 것 입니다.
예를들어, 강아지, 고양이, 거북이를 분류하는 이미지 분류 모델이 있다고 가정해봅시다. 해당 모델은 강아지와 고양이 그리고 거북이를 잘 분류할 수 있으며, 두 종류 이상의 동물이 같이 등장해도 잘 분류할 수 있습니다. 하지만 이 모델에게 강아지가 먼저 나타났는지 고양이가 먼저 나타났는지는 중요하지 않습니다. 단지 이미지 내에 해당 동물이 ‘존재하는지’ 여부만이 중요하기 때문입니다.
하지만 언어는 그렇지 않습니다. 'On'과 'No'가 완전히 다른 의미인 것처럼, 이미지에 알파벳 'a'가 등장하는지 여부도 중요하지만 몇 번째 순서에 등장하는지 또한 굉장히 중요합니다.
CRNN
2015년에 공개된 Convolutional Recurrent Neural Network(CRNN)은 STR 모델을 Convolutional Layers, Recurrent Layers, Transcription Layer의 3 단계의 레이어로 구성하는 방법을 제시했습니다.
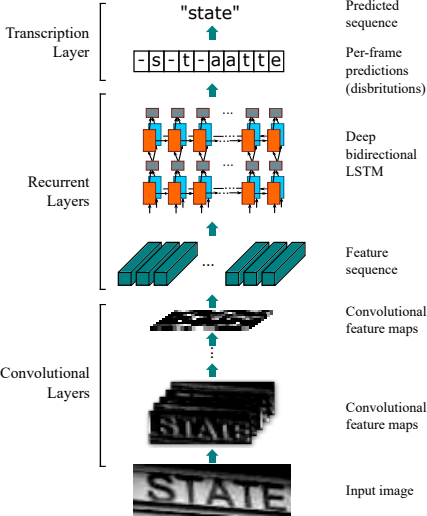
그림 1. Convolutional Recurrent Neural Network
Baoguang Shi (2015)
그림 1의 CRNN 모델 아키텍처를 보면, 1단계 Convolutional Layers는 CNN을 활용해 입력을 인코딩하는 작업을 수행합니다. 이는 곧 이미지의 특징(feature)을 추출하는 단계라고 할 수 있습니다. 2단계 Recurrent Layers는 RNN을 활용하여 추출된 특징에 시퀀스(sequence) 정보를 추가합니다. 모델이 실제 예측(Prediction) 시에 전후 입력 정보를 직접 고려하지 않기 때문에, 미리 앞뒤 픽셀에 대한 정보를 반영해주는 역할을 합니다. 마지막으로 3단계 Transcription Layer에서는 Connection Temporal Classification(CTC)를 이용해 최종 예측을 수행합니다.
inp = torch.randn([batch, 3, height, width]) # [b, 3, h, w]
cnn_oup = cnn_layer(inp) # [b, c_c, c_h, c_w]
rnn_inp = cnn_oup.permute(0, 3, 1, 2).view(b, c_w, c_c * c_h) # [b, c_w, c_c * c_h]
rnn_oup = rnn_layer(rnn_inp, batch_first=True) # [b, c_w, hidden_size]
pred_oup = prediction(rnn_oup) # [b, c_w, num_labels]
모델 내의 데이터 흐름(flow)은 코드를 통해 살펴보면 더 직관적입니다. Line 1과 2에서는 3채널의 RGB 이미지를 입력으로 받아 CNN 레이어에 통과시키는 과정을 확인할 수 있습니다. 이 때 각 라인의 주석은 출력 형태(shape)를 의미합니다. Line 3과 4에서는 c_w 단위로 RNN 레이어를 통과하는 과정을 확인할 수 있습니다. 마지막으로 Line 5에서 prediction function을 통과하면 최종 출력은 [b, c_w, num_labels]가 됩니다.
Feature Maps
Feature Map 추출은 데이터 인코딩과 동일한 과정입니다. CRNN에서는 CNN 레이어를 사용했지만, 최근 모델에선 transformer block을 활용해 준수한 성능을 보여주기도 합니다. 하지만 transformer block은 연산량 증가로 인한 추론 속도 저하라는 trade off가 발생합니다. 이러한 문제점에 비해 EfficientNet과 같이 최적화된 CNN 모델에 비해 성능이 더 좋다고 단정하기도 어렵습니다.
따라서 모바일 환경과 같은 소형 기기에서는 CNN 레이어를 활용한 소형 모델로도 충분할 것입니다. 반면 성능이 매우 중요하다면 대량의 데이터로 transformer block 기반의 OCR 모델을 학습시키는 것도 좋은 방법이 될 수 있습니다.
Connection Temporal Classification
CTC를 사용하는 핵심적인 이유는 모델의 출력 시퀀스 길이가 정답 시퀀스보다 훨씬 길 수 있다는 점입니다. 그림 1의 예시를 보면, 모델은 ‘state(5)‘라는 정답을 얻기 위해 ‘-s-t-aatte-’(11, c_w)와 같은 긴 정답 시퀀스를 생성했습니다.
CTC는 이 모든 경우의 수를 동적 프로그래밍(Dynamic Programing, DP)을 사용해 모든 정답 시퀀스 중에 가장 높은 확률을 갖는 정답 시퀀스를 찾아냅니다. 좀 더 상세한 알고리즘은 Connectionist Temporal Classification(ratsgo’s SPEECH BOOK)을 살펴보는 것을 추천드립니다.
Sequence
최근에는 CTC가 아닌 Auto Regressive(AR) 모델을 이용해서 추론하는 것이 더 주된 방법입니다. 그림 1의 Recurrent Layers에는 인코딩 과정만 있고 디코딩 과정이 빠져있습니다. Sequence Recognition Network(SRN)에서는 CRNN에선 빠졌던 RNN 디코더를 사용해 정답 시퀀스를 추론했습니다.
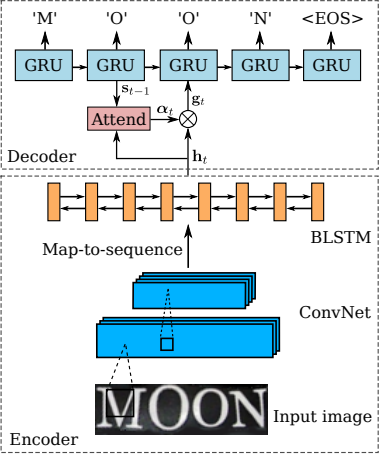
그림 2. Sequence Recognition Network
Baoguang Shi (2016)
RNN 디코더를 사용했을 때의 가장 큰 장점은 언어적 맥락을 활용할 수 있다는 점입니다. CTC와 달리, RNN 디코더는 ‘he’가 생성된 후 ’llo’가 나올 확률이 높다는 것을 모델이 학습합니다. 이는 이미지가 손상되어 ‘hellc’처럼 보이더라도 우리가 ‘hello’라고 읽는 것처럼, 노이즈(noise)에 강건한(robust) 성능을 보여줍니다. 그 밖에도 Attention 메커니즘과
Reference
[1] Baek, Jeonghun (2019) | What Is Wrong With Scene Text Recognition Model Comparisons? Dataset and Model Analysis
[2] Graves, Alex (2006) | Connectionist Temporal Classification: Labelling Unsegmented Sequence Data with Recurrent Neural Networks
[3] Shi, Baoguang (2015) | An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition
[4] Shi, Baoguang (2016) | Robust Scene Text Recognition with Automatic Rectification
[5] Scene Text Recognition Recommendations