
Scene Text Recognition (2/2)
Scene Text Recognition(STR)의 module로써 Language Model(LM)을 사용해 성능을 높히는 경우가 더러 존재한다. 경우에 따르지만 대부분 유의미한 성능 향상을 보여준다. 이는 우리가 다루는 텍스트가 단순히 무작위 문자의 나열이 아닌 순서에 따라 의미가 바뀌는 데이터이기 때문이다. 그리고 이런 언어적 지식을 텍스트 이미지를 통해 학습하는 것은 한계가 존재한다.
#
언어적 지식이란 추상적인 개념에 대해 예시를 통해 알아보자. 만약 6면체 주사위를 두 번 던져서 두 눈의 합이 4보다 클지 작을지를 필자에게 예측해 보라고 한다면 클 것 같다고 예측할 것이다. 왜냐하면 주사위의 모든 면이 나올 확률이 동일하다고 할 때, 두 눈의 합은 4보다 클 확률이 작을 확률보다 10배 높기 때문이다. 4보다 작을 확률이 존재하지 않는 것은 아니지만, 크다고 예측하는 것이 정답일 확률이 10배 높다. 텍스트도 마찬가지다.
 Figure 1. Likelihood에 따른 예측 확률 (조, 즈)
Figure 1. Likelihood에 따른 예측 확률 (조, 즈)
위의 이미지는 노이즈로 인해 ‘치즈’와 ‘치조’ 두 가지 모두 정답일 확률이 존재하며 두 단어는 모두 사전에 등재되어 있다. 하지만 만약 둘 중 하나가 정답이며 선택해 보라고 하면, ‘치조’를 고르는 사람보다는 ‘치즈’를 고르는 사람이 많을 것이다. 그럼 이 선택은 과연 올바른 선택일까?
*조* : *즈* = 11,150,298 : 1,104,950
*치조* : *치즈* = 1,070,574 : 115,125
치조 : 치즈 = 0 : 3,804
2009~2018년 사이에 발행된 신문 기사에서 각 표현이 사용된 횟수 (데이터 출처 : 모두의 말뭉치)
신문 기사에서 ‘조’와 ‘즈’가 사용된 횟수에 대해 조사해 보았다. ‘조’가 ‘즈’에 비해 10배 가까이 많이 사용되었다. ‘조’와 ‘즈’ 사이에서 정답을 예측해야 한다면 ‘조’를 선택하는 편이 정답일 확률이 10배 가까이 높다는 것이다. ‘치’라는 글자가 앞에 온다 해도 마찬가지다. ‘치조’가 ‘치즈’보다 10배 가까이 확률이 높다.
하지만 ‘치즈’와 ‘치조’가 단일 단어로 존재하게 되면 얘기가 달라진다. 표본 집단에서 ‘치조’라는 문자가 단일 단어로 사용된 횟수는 0이다. ‘치즈’라고 예측하는 편이 월등히 높은 정답 확률을 보장한다.
#
LM이 하는 일은 어디까지나 보정이다. Scene text recognition의 경우, Fig.1처럼 노이즈가 존재하는 이미지는 이미지만으로 정확한 예측이 불가능하다. 그렇기 때문에 노이즈에 대해 얼마나 제대로 예측하냐에 따라 모델의 성능이 크게 갈린다. LM은 이러한 선택의 갈림길에서 좀 더 높은 확률의 정답을 제시해준다. LM이 하는 일은 정답을 예측하는 일이 아닌 정답의 확률을 제시하는 것이다. 최종적으로는 이미지를 통한 예측 확률과 LM에서의 예측 확률이 합쳐져 최적의 정답을 만들어낸다.
아마 딥 러닝에 대한 조예가 싶다면 STR의 sequentialization 파트가 그 역활을 대신할 수 있는데 왜 LM을 쓰는지 의문을 가질 수 있다. 필자가 생각하는 이상적인 모델 또한 LM을 사용하지 않고 sequentialization 파트에서 이런 지식을 학습하는 것이다. 하지만 그것은 현실적으로 불가능하다. LM에서 다루는 데이터는 텍스트고, STR에서 다루는 데이터는 이미지이기 때문이다. LM에서 다루는 텍스트의 양과 동일한 이미지를 구하는 것도 학습시키는 것도 현실적으로 어렵다.
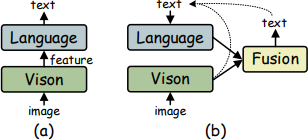 Figure 2. (a) Coupled language model / (b) ABINet autonomous language model
Figure 2. (a) Coupled language model / (b) ABINet autonomous language model
Fig.2의 이미지는 Autonomous, Bidirectional and Iterative Language Modeling for Scene Text Recognition (ABINet)에서 발췌한 것이다. (a)가 기존 STR 모델이고 (b)가 ABINet에서 채용한 구조이다. 주목할 부분은 LM 입력값의 형태다. 기존 STR 모델은 image feature가 입력이 되고, ABINet은 text가 입력이 된다. 이 차이로 인해 ABINet에서는 pre-trained LM을 사용할 수 있게 되고, 이는 곧 추가적인 언어적 지식을 습득하는게 가능하다는 것이다.
#
Language model의 원리는 위에서 다룬 통계적 지식이다. Language model은 단어들의 sequence에 대한 확률을 기억하고 조합을 학습한다. 예를들어 ‘감자튀김’이란 단어는 ‘감자’와 ‘튀김’의 합성어다. 이런 정보를 STR 모델이 scene text image를 통해 자체적으로 학습하는 것은 현재로서는 불가능에 가깝다.
누군가는 STR 모델이란 word box 내의 문자를 텍스트로 변환해 줄 뿐인 모델인데, 어째서 그 언어적 의미까지 알아야 하는가에 대해 의문이 들 수 있다. 사실 문자의 semantic을 이해하는 것이 STR 모델에 어떠한 영향을 주는지, 딥러닝의 특성상 정확하게 알 수는 없다. 하지만 확실한 것은 STR 모델에서 semantic이 노이즈로 작용할 이유는 없어 보이며, 수 많은 텍스트와 그 언어적 지식을 학습하는 것은 어떤 형태로든 STR 모델에 도움이 되고 있는 것이 실험으로 증명되고 있다.
LM은 어디까지나 보정의 역활이다. Graph convolutional network for Textual Reasoning (GTR)같은 논문에서는 STR을 보정하는 LM을 보정하는 GTR을 개발하고 발표했다. 필자의 생각은 이런 보정 모듈들은 어디까지나 임시 방편이라고 생각한다. 아마 머신 러닝 엔지니어와 사이언티스트들이 이상적으로 생각하는 모습은 아닐 것이다. 하지만 지금 당장은 선택이 아니라 필수라고 생각한다.
Experience
Model Framework : https://github.com/FangShancheng/ABINet
공개된 오픈 소스에서 도커 파일을 함께 제공하고 있기에, LM을 pre-train 하는 것을 제외하고는 문제가 없을 것이라 생각한다. 원본의 경우 LM의 학습에 WikiText-103를 사용하였는데, 유사한 형태의 한글 데이터가 존재하지 않는다.
Wikitext-103의 경우 100m 규모의 word tokens을, feature article 혹은 good article에서 추출했는데, 한국어 위키에서 feature article에 해당하는 알찬 글은 그 규모가 빈약하다.
필자가 생각하기에 가장 좋은 LM의 학습 셋은 본인이 테스트할 도메인에 따라 수집하는 것이 좋으므로, 100m 규모의 어느 정도 정규화된 word token dataset이면 문제 없을 것이라고 생각한다. 잘 모르겠다면 모두의 말뭉치나 kowiki dump를 활용하자
Reference
[1] S. Fang, et al. Read Like Humans: Autonomous, Bidirectional and Iterative Language Modeling for Scene Text Recognition
[2] Y. He, et al. Visual Semantics Allow for Textual Reasoning Better in Scene Text Recognition